 公開日
公開日 最終更新
最終更新 記事区分
記事区分Dataflow は Apache Beam のマネージドサービスです。大規模データの分散処理が可能になります。簡単な使い方を記載します。
Dataflow テンプレートを用いる場合
GCP が提供するデータ処理のテンプレートを利用すると、Apache Beam の使い方を把握していなくても Dataflow を利用できます。
ここでは簡単な例として、Cloud Storage (GCS) 上の CSV ファイルを、DLP API によって de-identification して、BigQuery に書き出すデータフローのテンプレートを使ってみます。
DLP テンプレートの準備
PERSON_NAME を検出する inspection-template を作ってみます。

de-identification-template は、CSV の特定のカラムのみ匿名化したいため、Record を選択しています。

匿名化したいカラムのヘッダーは pii であるとします。pii カラムのデータについて、検出された箇所を info type 名で置換するように設定しています。

「テスト」タブで動作検証できます。inspection-template を指定することを忘れないようにします。pii 列の PERSON_NAME が匿名化されていることが分かります。

BigQuery データセットの準備
DLP で匿名化したデータを格納する BigQuery のデータセットを準備します。
bq mk mydataset_20210501
GCS バケットの準備
DLP で匿名化したいデータを格納する GCS バケットを準備します。
gsutil mb gs://mybucket-20210501-4
サービスアカウントの準備
GCP の Compute Engine サービス等を有効化すると、以下のようなサービスアカウントが作成されます。
{project-number}-compute@developer.gserviceaccount.com
既定では Dataflow はこのサービスアカウントを用いて、必要な VM を起動したりします。プロジェクトの Editor ロールが付与された状態で作成されますが、更に Cloud Dataflow Service Agent ロールを付与しておきます。

Dataflow ジョブの作成
Dataflow template に Data Masking/Tokenization from Cloud Storage to BigQuery (using Cloud DLP) を指定します。

GCS、Bigquery、DLP de-identification template の情報を指定します。

DLP inspection template の指定は必須ではありませんが、今回 PERSON_NAME 以外は検出してほしくないため、指定します。更に、Dataflow が起動する VM のタイプや台数、Dataflow が利用するサービスアカウント等を指定します。

ストリーミングタイプの Dataflow Job が作成されたことが確認できます。

指定した台数の VM が起動しています。

GCS への CSV ファイルアップロード
Dataflow Job のパラメータとして指定した GCS のパスに、CSV ファイルをアップロードします。
gsutil cp pii-sample.csv gs://mybucket-20210501-4/input/
pii-sample.csv
pii,non_pii
My name is Mike,My name is Mike
My phone number is 090-1234-1234,My phone number is 090-1234-1234
pii カラムの PERSON_NAME が匿名化されたことが確認できます。

Apache Beam 2.x Java SDK の利用例
先程用いた DLP による匿名化のテンプレートは、De-identification and re-identification of PII in large-scale datasets using Cloud DLP に記載されているユースケースの一つをサポートしています。
Dataflow テンプレートをそのまま利用できない場合は、Apache Beam SDK を用いて開発する必要があります。言語は Java または Python がサポートされています。以下では、既存のテンプレートを編集してカスタマイズする場合を想定しています。
Java8 および Maven3 のインストール
Dataflow テンプレートはオープンソースとして GitHub で公開されています。
git clone git@github.com:GoogleCloudPlatform/DataflowTemplates.git
テンプレートは Java で記述されています。Java8 および Maven3 をローカル環境にインストールして、以下のようにビルドできます。
mvn clean compile
Java15 等ではビルドできないことに注意します。
$ mvn --version
Apache Maven 3.8.1 (05c21c65bdfed0f71a2f2ada8b84da59348c4c5d)
Maven home: c:\Users\username\bin\apache-maven-3.8.1\bin\..
Java version: 1.8.0_291, vendor: Oracle Corporation, runtime: C:\Program Files\Java\jdk1.8.0_291\jre
Default locale: ja_JP, platform encoding: MS932
OS name: "windows 10", version: "10.0", arch: "amd64", family: "windows"
DLPTextToBigQueryStreaming.java をテストするには以下のようにします。
mvn test -Dtest=DLPTextToBigQueryStreamingTest
実行結果の例
[INFO] Results:
[INFO]
[INFO] Tests run: 1, Failures: 0, Errors: 0, Skipped: 0
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 44.991 s
[INFO] Finished at: 2021-05-02T17:29:09+09:00
[INFO] ------------------------------------------------------------------------
BigQuery データセットの準備
DLP で匿名化したデータを格納する BigQuery のデータセットを準備します。
bq mk mydataset_20210501
サービスアカウントの準備
ローカルPC で DLP API を実行して、結果を BigQuery に格納するためのサービスアカウントを準備します。

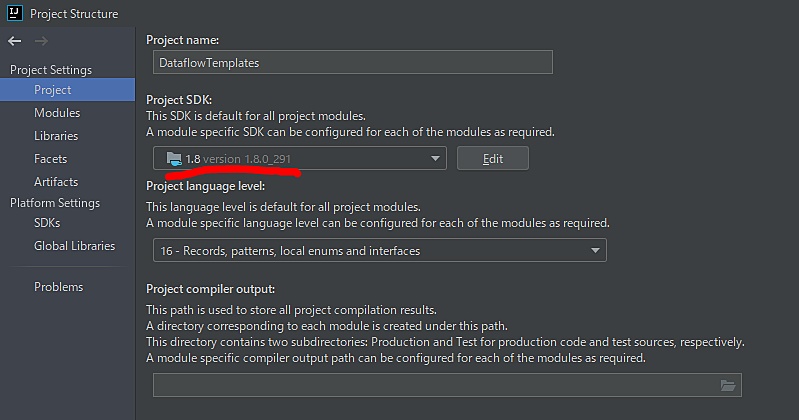
IntelliJ IDEA の設定
開発環境として IntelliJ IDEA を利用する場合は、DLPTextToBigQueryStreaming.java を以下のように実行できます。
「File → Project Structure...」で JDK8 を指定することを忘れないように注意します。
ローカル PC でのビルドおよび実行
ビルドした結果を GCS にアップロードして Dataflow Job を作成することでもソースコードの検証は行えます。そうではなく、ローカルPC で直接 Java を実行するには以下のようにします。
「Run → Run... → Edit Configurations...」
Environment variables に GOOGLE_APPLICATION_CREDENTIALS を設定して、サービスアカウントの鍵ファイルを指すようにしておきます。更に、Program arguments に必要な情報を指定しておきます:
--project=my-project-20210328
--dlpProjectId=my-project-20210328
--inputFilePattern=C:\Users\username\Desktop\pii-sample.csv
--inspectTemplateName=projects/my-project-20210328/locations/global/inspectTemplates/my-inspection-template-20210501
--deidentifyTemplateName=projects/my-project-20210328/locations/global/deidentifyTemplates/my-deidentification-template-20210501
--datasetName=mydataset_20210501

実行結果の例

BigQuery にも正しく格納されました。

Apache Beam 2.x Python SDK の利用例
インストール
Python から Apache Beam を利用するためには apache-beam をインストールします。setup.py に記載のとおり、GCP API を利用するための GCP_REQUIREMENTS も依存モジュールとしてインストールするように指定します。
python3 -m pip install apache-beam[gcp]
簡単なサンプル
my-dataflow-1.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
from argparse import ArgumentParser
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import SetupOptions
from apache_beam.io import ReadFromText
import logging
logging.getLogger().setLevel(logging.INFO)
def Main():
parser = ArgumentParser()
parser.add_argument(
'--input', type=str,
default='gs://dataflow-samples/shakespeare/kinglear.txt',
help='Input file to process [default=%(default)s]')
knownArgs, pipelineArgs = parser.parse_known_args()
pipelineOptions = PipelineOptions(pipelineArgs)
pipelineOptions.view_as(SetupOptions).save_main_session = True
# パイプラインは with ブロックを抜けた時に実行されます。
with beam.Pipeline(options=pipelineOptions) as p:
lines = p | 'read from text' >> ReadFromText(knownArgs.input)
lines | beam.Map(print)
if __name__ == '__main__':
Main()
Apache Beam SDK には runner という概念があります。既定では DirectRunner が使われてローカル実行されます。
python3 my-dataflow-1.py --input ~/Desktop/pii-sample.csv
出力例
INFO:root:Missing pipeline option (runner). Executing pipeline using the default runner: DirectRunner.
...
pii,non_pii
My name is Mike,My name is Mike
My phone number is 090-1234-1234,My phone number is 090-1234-1234
DataflowRunner を指定して、その他の必要なオプションを pipelineArgs に渡すことで、GCP Dataflow で処理を実行できます。
export GOOGLE_APPLICATION_CREDENTIALS='C:\Users\username\Downloads\my-project-20210328-04084aee5ee7.json'
python3 my-dataflow-1.py \
--project my-project-20210328 \
--region us-central1 \
--runner DataflowRunner \
--staging_location gs://mybucket-20210501-4/staging \
--temp_location gs://mybucket-20210501-4/temp
作成された Dataflow Job

その他
Apache Beam で分散処理を行う際に必要となる関数の使い方は、以下のようなページに記載されています。
Apache Beam SDK で作成したパイプラインの利用方法について
Apache Beam SDK で DirectRunner を用いてローカル開発したパイプラインは、DataflowRunner で GCP 上で実行できます。
実行方法としては、以下の二つがあります。
- 本ページで行ったように GCS に staging するのと同時に Job を作成する方法。
- GCP で用意されているテンプレートのように GCS へのアップロードのみを行い、Dataflow Job は必要な時に Cloud Console (Web UI) 等から作成する方法。
更に後者については、Classic templates と Flex Templates の二つの選択肢があります。

記事の執筆者にステッカーを贈る
有益な情報に対するお礼として、またはコメント欄における質問への返答に対するお礼として、 記事の読者は、執筆者に有料のステッカーを贈ることができます。
さらに詳しく →
Feedbacks

ログインするとコメントを投稿できます。
関連記事
- GKE における Node および Pod の autoscaling
 Google Kubernetes Engine (GKE) における autoscaling について、用語の意味を整理します。 GKE の機能による Node の autoscaling GKE のクラスタには Standard と Autopilot の二種類が存在します。 Autopilot の場合は Node は Google によって管理されるため、自動で autoscaling され...
Google Kubernetes Engine (GKE) における autoscaling について、用語の意味を整理します。 GKE の機能による Node の autoscaling GKE のクラスタには Standard と Autopilot の二種類が存在します。 Autopilot の場合は Node は Google によって管理されるため、自動で autoscaling され... - Snowflake におけるネットワーク関連の設定
 本ページではネットワーク関連の設定について記載します。 Network Policy によるアクセス元 IP 制限 IPv4 で指定します。IPv6 は 2021/9/21 時点では利用できません。 allowed list で許可されていない IP は block されます。 allowed list が /24 等で指定されており、その一部を
本ページではネットワーク関連の設定について記載します。 Network Policy によるアクセス元 IP 制限 IPv4 で指定します。IPv6 は 2021/9/21 時点では利用できません。 allowed list で許可されていない IP は block されます。 allowed list が /24 等で指定されており、その一部を - VPC Service Controls に関する雑多な事項の整理
 VPC Service Controls (VPC-SC) に関する雑多な事項を記載します。 Private Google Access の基本形 Private Google Access は外部 IP を持たない VM のための機能です。VPC の機能ですが、VPC-SC と関連するため基本事項を記載します。 [Private Google Access](ht
VPC Service Controls (VPC-SC) に関する雑多な事項を記載します。 Private Google Access の基本形 Private Google Access は外部 IP を持たない VM のための機能です。VPC の機能ですが、VPC-SC と関連するため基本事項を記載します。 [Private Google Access](ht - AWS IAM Role を GCP から STS 認証で利用する設定例
 GCP から AWS IAM Role を利用するための設定例を記載します。 GCP Service Account の作成 Service Account を作成して Unique ID を確認します。 AWS IAM Role の作成 Trust relationship の設定は Web Identity を選択します。Identity Provider
GCP から AWS IAM Role を利用するための設定例を記載します。 GCP Service Account の作成 Service Account を作成して Unique ID を確認します。 AWS IAM Role の作成 Trust relationship の設定は Web Identity を選択します。Identity Provider - Amazon Comprehend を GCP VPC 内から実行する設定の例 (Public Internet 接続なし)GCP DLP に相当する AWS サービスに Amazon Comprehend が存在します。GCP VPC 内から Public Internet を経由せずに利用する設定の例を記載します。 AWS VPC と GCP VPC の作成 クラウド 項目 値 AWS VPC region ap-northeast-1 AWS VPC CIDR 10.2.0.0/16 AWS ap-north




